A rato de no escribir en el PuroAC hoy explicaré una técnica muy usada en programación, pero sobre todo en la programación competitiva. A raíz de que recientemente me ha sido útil y con el fin de compartir los conocimientos (además de que en mi otro blog donde lo explicaba murió el post).
La memoización (Memoization en inglés) o memorización se diferencia de 'memorización' puesto que el término ya era usado en matemáticas, es una técnica que ayuda a la aceleración de cómputo en una función recursiva en el momento en que se tarde bastante y se hagan las mismas llamadas a la función que ya fueron hechas anteriormente.
¿Ejemplo?
Todos conocemos la función de Fibonacci... ¿no?Sino, la explico rápido. La función de Fibonacci empieza con los casos triviales o base
$Fibo(0) = 1$ y $Fibo(1) = 1$
y de ahí se deriva la serie siendo $Fibo(2) = Fibo(1) + Fibo(0)$
o sea que nuestra función de Fibonacci esta dada por
$Fibo(n) = Fibo(n-1) + Fibo(n-2)$ siendo $n>=2$
$Fibo(n) = Fibo(n-1) + Fibo(n-2)$ siendo $n>=2$
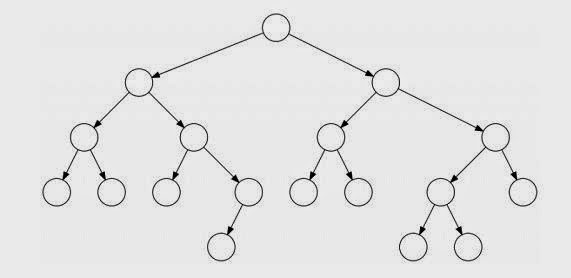
Veamos el árbol que se forma para su cálculo...
En el caso de implementar esta función de manera recursiva, otro ejemplo para la llamada de la función podría ser con $n = 5$

Cuando se llega en el árbol a los casos base (señalados en la imagen) evidentemente las llamadas a la función se detienen. Pero también podemos notar que existen varios casos en donde se llama recursivamente a números que ya fueron calculados, por ejemplo el 3.

Entonces para subsecuentes llamadas la cantidad de operaciones a calcular se volverían exponenciales y la complejidad aproximada sería $O(2^n)$ lo cuál para un $n = 40$ ya es mucho que calcular.
La optimización.
Por fortuna nos podemos ayudar de la memoización para mejorar el rendimiento de nuestra función.
Básicamente la idea es tener un arreglo del tamaño de la $n$ que queramos calcular y llenarlo de valores "bandera" (por ejemplo $-1$) y mientras se van calculando todas las $Fibo(n)$ en cada una de las llamadas recursivas esos valores obtenidos meterlos en el arreglo correspondiente a la $n$ actual.
Básicamente la idea es tener un arreglo del tamaño de la $n$ que queramos calcular y llenarlo de valores "bandera" (por ejemplo $-1$) y mientras se van calculando todas las $Fibo(n)$ en cada una de las llamadas recursivas esos valores obtenidos meterlos en el arreglo correspondiente a la $n$ actual.
Aquí el código de la función en Python sin optimización:
def fiboLento(n): if n == 0 or n==1: return 1 return fiboLento(n-1) + fiboLento(n-2)
Así pues con la optimización:
memo = [-1 for i in xrange(100000)] def fibo(n): if n == 0 or n==1: return 1 if memo[n]!= -1: return memo[n] memo[n] = fibo(n-1) + fibo(n-2) return memo[n]Justamente en esta línea de código es donde preguntamos si el valor de Fibonacci para nuestra actual n ya fue calculado.
if memo[n]!= -1: return memo[n]¿Cómo lo sabemos? Pues fácil sí nuestro arreglo en la posición $n$ ya no tiene $-1$ como valor es que ya fue calculado antes es ahí donde solo debemos devolver el valor para esa $n$ y así no rehaga el cálculo para todos sus hijos en caso de que los tenga.
Conclusión.
Sí, generalmente memoizar es tan fácil como solo ir coleccionando los cálculos que hagamos y preguntar si se tiene hasta ese momento (en el estado actual de la llamada recursiva) calculado el valor si sí, no se calcula y se devuelve el valor, pero hay que tener cuidado de que nuestro árbol se pueda podar y asegurarnos que las ramas que vayamos a podar sí se calculen en algún otro punto del árbol.

Ahora el árbol nos quedaría más o menos así, ya que todas las llamadas a las n que ya fueron calculadas solo devuelve su mismo valor, lo cual reduce la complejidad aproximadamente a $O(n)$. Considerablemente se ha reducido la complejidad del cálculo.
Si bien pudimos hacer un ciclo for para calcular Fibonacci de n, use está función porque es fácil de entender y fácil para ejemplificar el uso de la Memoización pero existe una cantidad muy vasta de problemas donde podemos aplicarla.
Si tienes dudas puedes escribirme a @ferprogramming en twitter. Saludos.















.jpg)



